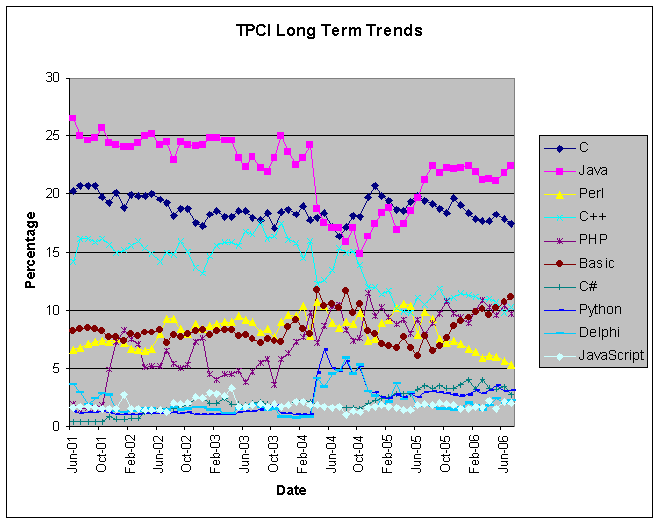
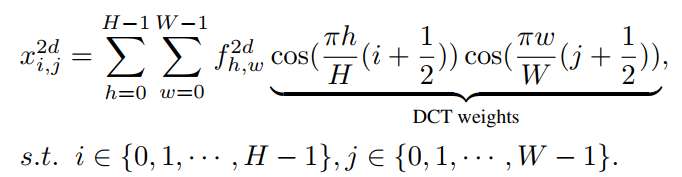- 这是CVPR2021的一篇论文
开放世界目标检测:
-
在没有提供相关监督的情况下将无法分类的目标检测出来标记为unknown
-
能够在后续提供这些标签时,不忘记之前的类别同时渐进地学得这些unknown的类别
-
其实质是open set learning和incremental learning的结合
-
现有检测器其实不太合理,将未标注的目标和背景混为一谈,导致训练空间其实是个畸形的不合理的空间。这导致某些未标注的类别还是被分类成错误的前景类别,假阳率很高
-
并且,实际投入应用中,如自动驾驶,不可能事先把所有可能的类别都找出来进行训练,总是会遇到未标注未训练过的样本的,因此开放世界目标检测是个更加合理的模型
-
当算法预测出未知类别时,需要人力观察未知类别,然后提供增量训练样本,使得模型学得新类别。
模型方法:
-
主要思路是在隐空间中去聚类,把不属于当前已标记类别的特征分类为unknown,具体如下:
-
取二阶段目标检测网络某个中间层的特征向量作为隐空间变量,对于每个类别都有一个聚类中心,通过一个loss函数来希望每个图片的这个特征离自己类别的聚类中心近一点,离其它类别的远一点:

-
通过最小化上述loss函数,来获得一种效果:在这个隐空间中,相同类别的ROI,其隐变量分布在较近的距离,而不同类别的较远,因此当一个ROI的隐变量离所有已知类别的聚类都很远时,说明这个ROI是unknown类,也即未标注类别。
-
正常来讲,这个 p i p_i pi应该是该类别所有隐变量的均值,但是网络是训练的,所以对每个样本通过网络提取的隐变量会随着训练而变化,均值也会变化,所以 p i p_i pi也要变化。所以需要一个明确的更新算法,本文提出的算法如下:

-
意思就是,每隔 I I I次迭代,用各个类别各自最近 Q Q Q次迭代的样本的特征向量(也就是前面一直说的隐变量)来算各个类别的均值,然后和老的聚类中心做加权平均(平滑),作为各个类别新的聚类中心。当然一开始没有 Q Q Q个样本来算聚类中心,所以一开始的loss先按0来算,迭代 I I I次之后才开始算loss
-
上述训练需要unknown样本,从RPN中获取,当某个ROI与所有标记的GT都不重叠时,当作unknown样本,并且只取输出score最高的前k个。
-
当训练结束,推测阶段,基于一个输入特征向量F,该模型利用一个基于能量的模型去计算获取其预测类别,这里解释下什么是基于能量的模型:
-
基于能量的模型(EBM)把我们所关心变量的各种组合和一个标量能量联系在一起。我们训练模型的过程就是不断改变标量能量的过程,因此就有了数学上期望的意义。比如,如果一个变量组合被认为是合理的,它同时也具有较小的能量。基于能量的概率模型通过能量函数来定义概率分布,可以用梯度下降法来训练。
-
具体而言,基于能量的模型有下列公式:
p ( x ) = e − E ( x ) ∑ x e − E ( x ) p(x) = \frac{e^{-E(x)}}{\sum_{x}{e^{-E(x)}}} p(x)=∑xe−E(x)e−E(x)
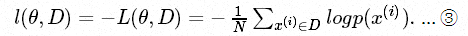
-
本模型使用的能量模型公式如下:

-
这里的g就是网络的全连接层的输出,普通的网络就是把g接到softmax去做分类的,这里利用了g构建了E,这个E的意义在于,对于不同的输入f,有不同的能量标量值与之对应,而由于在隐空间将已知类别和未知类别分得很开,所以这里已知类别的特征向量输入产生的能量和未知类别的特征向量输入产生的能量值有较大区分,如下图所示:

- 为了找到区分known和unknown的能量值阈值,用韦伯分布去拟合两部分数据,得到两个韦伯分布,因此对于一个特征向量输入,产生一个能量值,能量值在两个分布上对应了两个概率密度,当在known分布上的概率密度值高于unknown分布上的概率密度值时,认为该特征来自一个已知类别,否则来自未知类别。之所以是韦伯分布,是实验出来的,比伽马分布、正态分布、指数分布都更优
- 这样一来,在实现上其实只是分为两步,首先通过能量值判断是不是known;若是known,再看哪个类别的输出值更高,这点和原来的没有差别。
- 至于如何根据新增加的样本,在不忘记原来类别的基础上进行增量学习,本文并没有提出新的方法,而是沿用了已有的方法。
- 模型结构如下:

- 相较原有模型,该模型只是增加了一个loss,并且修改了分类层为能量模型